AI業界に激震が走っています。中国のAI企業 DeepSeekがリリースしたAIモデルが、OpenAIのo1モデル並みの性能を持ちながらオープンソース公開されているようで、高性能LLMが自宅環境でも構築できるようになり、恐怖さえ感じます。
本記事ではDeepSeek R1について解説しますので、ぜひ最後までご覧ください。
🕒 「生成AIお悩み相談室」30分無料相談のご案内
\今だけの特別枠、予約殺到中!/
「生成AIを導入したいけど何から始めれば?」「ChatGPTをビジネスに活用する方法は?」「コスト削減のためのAI活用法を知りたい」
このような疑問や課題をお持ちではありませんか?
当社の生成AIスペシャリストが、あなたのビジネス課題に合わせた具体的なアドバイスを完全無料で提供します。
✅ 30分で得られる価値
- 貴社の業務に最適な生成AI活用法の提案
- コスト削減・業務効率化のための具体的なステップ
- 競合他社に差をつけるAI戦略のヒント
- 内製化に向けたロードマップの相談
✅ 参加者からの声
「相談後すぐに実践できるアイデアが得られました」
「具体的な導入ステップが明確になり、迷いがなくなりました」
【完全無料・30分枠】数に限りがございますので、お早めにご予約ください。
👉 今すぐ無料相談を予約する 👈
※予約は先着順・毎月限定5枠のみ。キャンセル待ちにならないようお早めに。
ホワイトペーパー
Power Apps が理解できる3点セット

【下記の3点の資料が無料でダウンロードできます】
・Powe Apps 活用事例集
・【MS365で使える範囲も分かる】PowerAppsのライセンス早見表
・【担当者のスキルレベルや導入の進め方から判断!】PowerPlatformで内製化をすすめるためのロードマップ
DeepSeek R1とは?
DeepSeek R1 は、中国のAI企業 DeepSeek が開発した自己思考型のAIモデルです。
OpenAIのo1モデルに匹敵する性能を持ちつつ、最近オープンソースで無料公開されたことで話題を呼んでいます。
安価に高性能AIが作れるかも?とのことで、AI業界で価格破壊が起こる可能性を秘めています。既存の有料サービスに激震が走っており、今後のAI利活用に影響を与えるモデルなのは間違いないでしょう。
DeepSeek-R1の特徴

DeepSeek R1 は、DeepSeek社が開発した第一世代の推論モデルです。DeepSeek R1-Zero という前段階のモデルをベースに、強化学習(RL)をメインにトレーニングされています。
このアプローチにより、DeepSeek R1 は、数学、コード生成、推論タスクにおいて、OpenAI の o1 シリーズに匹敵する性能を達成しています。さらに、DeepSeek R1 から派生した軽量モデルも開発されており、こちらも優れた性能を発揮します。
・強力なReasoning能力
強化学習を用いた革新的なアプローチにより、特に数学や科学的推論において優れた性能を発揮。
・オープン
MITライセンスのもとで提供さている。
・低コスト
API価格が「OpenAI o1」の25分の1以下と、非常に低価格で利用できる。
・長いコンテキスト長
最大128Kトークンのコンテキストを扱えるため、長文の処理や要約に優れている。
人間のような思考力
DeepSeek R1 は、複雑な問題を解くときに、まるで人間が考えるように、段階的に論理を組み立てて答えを導き出す「推論」が得意。
従来のAIモデルよりも、自分で間違いに気づいて修正したり、複雑な問題を理解する力が高いです。
オープンソースで低コスト
DeepSeek R1 は、誰でも無料で利用できる「オープンソース」モデルです。性能が高いにもかかわらず、APIの利用料金もOpenAIのモデルと比較して大幅に安いという始末。
DeepSeekのAPIはChatGPTより27倍安いです。同じワークロードで270ドル対10ドルです。これは新しいグラフィックカードか格安キーボードのどちらかを選ぶようなもの。
様々な用途で活用可能
DeepSeek R1 は、質問応答、研究開発、コンテンツ作成、コーディングなど、幅広い分野で活用できます。
特に数学やコード生成の分野で高い能力を発揮します。
DeepSeek R1 の具体的な性能

DeepSeek R1 の性能を語る上で欠かせないのが、各種ベンチマークにおける結果です。ここでは、DeepSeek R1 がどのようなタスクで、どれほどの性能を発揮しているのか、具体的な数値データとともに詳しく解説します。
1. 推論能力:複雑な問題を解く力を測る
- AIME 2024 (Pass@1): 79.8%
- AIME(American Invitational Mathematics Examination)は、非常に難易度の高い数学の試験です。Pass@1 は、1回の回答で正解する確率を示します。
- DeepSeek R1 は、この難関試験において、79.8%という非常に高い正答率を達成しました。この数値は、OpenAI のo1-1217 と同等のレベルです。
- MATH-500 (Pass@1): 97.3%
- MATH-500 は、数学的な推論能力を測るベンチマークです。
- DeepSeek R1 は、このベンチマークで驚異的な97.3%という正答率を達成し、OpenAIのo1-1217 を上回る性能を示しました。
- この結果は、DeepSeek R1 が、高度な数学的な推論能力を持っていることを示しています。
2. コード生成能力:プログラミング能力を測る
- LiveCodeBench (Pass@1-CoT): 65.9%
- LiveCodeBench は、プログラムを生成する能力を測るベンチマークです。CoT (Chain of Thought) は、推論の過程を明示するプロンプトを用いた際の正答率を示します。
- DeepSeek R1 は、このベンチマークで65.9%の正答率を達成し、OpenAIのo1-1217 を上回る性能を示しました。
- これは、DeepSeek R1 が、高度なコード生成能力を持っていることを示唆しています。
- Codeforces (Elo Rating): 2029
- Codeforces は、プログラミングコンテストのプラットフォームで、参加者の実力を示すEloレーティングで評価します。
- DeepSeek R1 は、2029という高いレーティングを獲得しており、これは、OpenAIのo1-1217と同等のレベルです。
- この結果から、DeepSeek R1 は、プログラミングにおいても非常に高い能力を発揮することが分かります。
3. 知識・汎用能力:幅広い知識と応用力を測る
- MMLU (Pass@1): 90.8%
- MMLU (Massive Multitask Language Understanding) は、幅広い分野の知識を測るベンチマークです。
- DeepSeek R1 は、このベンチマークで90.8%という高い正答率を達成しており、幅広い知識と汎用的な能力を備えていることを示しています。
- GPQA Diamond (Pass@1): 71.5%
- GPQA (Google-Perplexity Question Answering) は、専門的な知識を必要とする質問応答を測るベンチマークです。
- DeepSeek R1 は、このベンチマークで71.5%の正答率を達成し、専門的な知識についても高い理解度を示しています。
4. 軽量モデルの性能:DeepSeek R1-Distill
DeepSeek R1 の優れた性能は、軽量モデルにも受け継がれています。特に、DeepSeek R1-Distill-Qwen-32B は、以下のベンチマークで、OpenAIのo1-mini を上回る性能を達成しています。
| モデル | AIME 2024 pass@1 | MATH-500 pass@1 | LiveCodeBench pass@1 |
| DeepSeek-R1-Distill-Qwen-32B | 72.6% | 94.3% | 57.2% |
| OpenAI-o1-mini | 63.6% | 90.0% | 53.8% |
この結果からも、DeepSeek R1-Distill モデルが、軽量でありながらも高い性能を発揮していることが分かります。
ベンチマーク結果から言えること
これらのベンチマーク結果から、DeepSeek R1 は、以下のような能力を持つことが分かります。
- 高度な推論能力: 数学的な問題解決や論理的な推論において、非常に高い能力を発揮する。
- 優れたコード生成能力: プログラミングにおいても、高い性能を発揮する。
- 幅広い知識: 専門的な知識から一般的な知識まで、幅広い分野で高い理解度を示す。
- 軽量モデルも高性能: DeepSeek R1-Distill モデルは、軽量でありながらも高い性能を発揮する。
DeepSeekの積極的な活用は危険?現在判明しているコトと不明なコト
すでに判明している、技術的特徴と注目点
すでに判明しているDeepSeek社の発表で特に注目されるのは、以下の点です。
- 大規模モデルと軽量モデルの同時公開
- 高性能を追求した大規模モデルと、エッジデバイスやローカル環境での利用を想定した軽量モデルを同時に公開したことで、幅広いユーザー層へのアプローチを可能にしました。
- MITライセンスによるオープンソース化
- 商用利用を含む広範な用途での活用を許可するMITライセンスを採用したことで、研究開発の加速と、ビジネスにおける新たな応用展開が期待されます。
- 強化学習によるモデル改良
- 公開された情報によれば、モデルの改良には強化学習を единственным 手法として用いていると推測されています。これは、データ収集とアノテーションに多大なコストを要する教師あり学習に比べ、効率的なモデル改善の可能性を示唆しています。
- 技術論文の公開
- モデルのアーキテクチャ、学習方法、評価結果などを詳細に記述した論文を公開することで、技術的な透明性を高め、コミュニティによる検証やさらなる発展を促進する意図が伺えます。
ビジネス活用の可能性と潜在的リスク
DeepSeek社のモデル公開は、企業における生成AIの活用を促進する上で、以下のような可能性とリスクをもたらすと考えられます。
- ローカル環境でのAI検証
- 軽量モデルを活用することで、クラウド環境に依存せず、セキュアな環境下でのPoC(概念実証)や性能評価が容易になります。特に、機密性の高いデータを扱う企業にとっては、AzureやAWSなどのクラウドAPIに頼らないローカル完結型のソリューションは大きな魅力となりえます。
- 既存システムへの組み込み
- オープンソースであるため、既存のシステムやソフトウェアへの組み込みが比較的容易であり、新たなアプリケーション開発や業務効率化に繋がる可能性があります。
- カスタマイズとファインチューニング
- 公開されたモデルと技術論文を基に、自社データを用いた追加学習や蒸留などのカスタマイズを行うことで、特定の業務や用途に最適化されたAIシステムを構築できる可能性があります。
判明されていない潜在的リスクと懸念事項
DeepSeekを今すぐ仕事で使うのはストップした方が良いかもしれません。理由は以下のとおり。
- ライセンスに関する不確実性 : 軽量モデルのライセンスが、ベースとなった大規模モデルのライセンスを適切に継承しているかについては、現時点では不明確な点があり、今後の精査が必要です。
- API価格の持続可能性 : APIの価格設定が、実際の運用コストを反映しているかについて疑問の声も上がっており、ビジネス利用においては、長期的なコスト構造の見極めが重要になります。
- 技術的負債とサポート体制 : オープンソースモデルの利用は、自社で技術的な負債を抱えるリスクを伴います。DeepSeek社からのサポート体制が不明確な現状では、技術的な専門知識を持つ人材の確保や育成が不可欠です。
- カントリーリスク : DeepSeek社は中国企業であるため、地政学的なリスクも考慮する必要があります。API利用や技術サポートの面で、将来的な不確実性が生じる可能性も否定できません。
企業が取るべき戦略
DeepSeek社の生成AIモデル公開は、企業にとって新たな選択肢となりえますが、現時点では慎重な評価と戦略的なアプローチが求められます。
- まずは技術検証から: 軽量モデルをローカル環境で動作させ、性能やcapabilitiesを評価することから始めるのが現実的です。特に、外部にデータを持ち出せない環境での利用を検討している企業にとっては、有用な選択肢となりえます。
- クラウドAPIとの比較検討: 現時点では、ビジネス利用においては、安定性、信頼性、サポート体制が確立されたAzure OpenAI Service、Google Gemini、Amazon BedrockなどのクラウドAPIが依然として有力な選択肢です。DeepSeekモデルの利用は、これらの既存サービスと比較検討した上で、費用対効果やリスクを総合的に判断する必要があります。
- オープンソースコミュニティへの貢献: DeepSeekモデルに限らず、オープンソースのAIモデルを活用する際は、コミュニティに貢献する姿勢が重要です。バグ報告、改善提案、技術情報の共有などを通じて、オープンソースエコシステムの発展に寄与することが、長期的な視点で見れば自社の利益にも繋がります。
Deepseek R1を実際に使ってみた
ウェブサイトにアクセスし、アカウントを作成またはログインします。
「DeepThink」ボタンをオンにすることで、DeepSeek-R1を利用できます。
Web検索機能との併用も可能です。
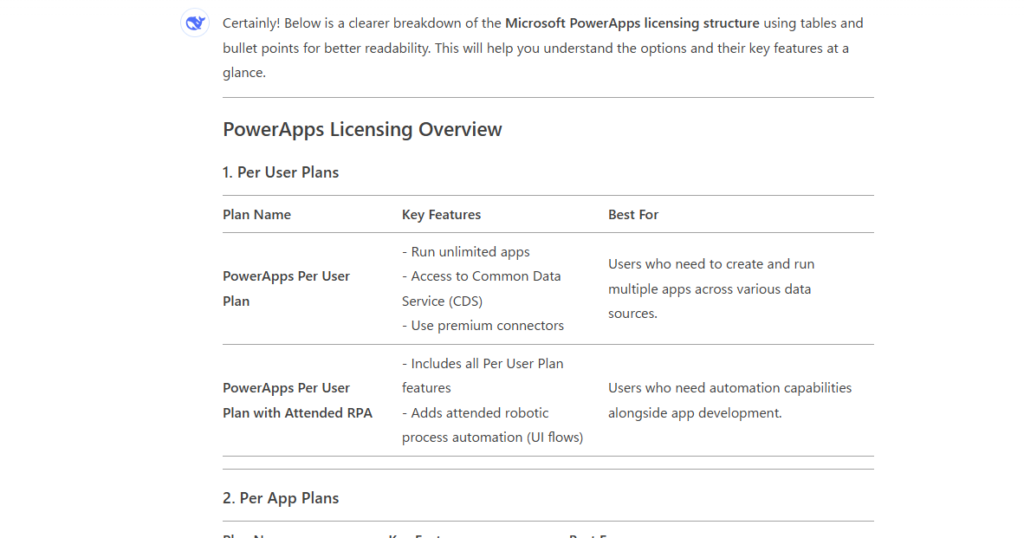
Power Appsのライセンス体系を聞いたところ、ほぼ間違いゼロの回答を瞬時にたたき出してくれました。
軽く使ってみて思った感想としては以下の通り。
- 日本語処理は少し弱め。英語・中国語が混ざった回答をする
- 基本的に英語・中国語でプロンプトを作成したほうがよい。出てきた回答をDeepLやLLMに翻訳してもらうとよいかも
- ただ、たまに架空の情報を教えてくるので注意
- 中華資本ということもあり、情報の取り扱いには一層気を付けるべき
中国製AI「DeepSeek」、絶対に1989年6月4日に何が起きたのか教えてくれないし、教えてくれない理由も教えてくれないし、話を逸らそうとしてくるのすごく良くできている。 pic.twitter.com/Y7PAGxvWfh
— 石井大智 (@Daichi_Ishii) January 22, 2025
DeepSeek R1 ができる過程がなかなか面白い
DeepSeek R1 が開発される過程が公開されているのですが、これがなかなかボリューミーで読みごたえがあります。全部英語でしたので翻訳してまとめました。
1. 強化学習の可能性を探る:DeepSeek R1-Zero の誕生
- ベースモデル:DeepSeek-V3-Base
- DeepSeek R1 の開発は、まずDeepSeek-V3-Base という高性能なAIモデルから始まりました。
- DeepSeek-V3-Base は、GPT-4o に匹敵する能力を持つにもかかわらず、オープンソースで利用できるという、非常に魅力的なモデルです。
- DeepSeek R1 は、この強力なベースモデルの性能を、さらに引き出すことを目指して開発されました。
- 教師あり学習を排し、強化学習のみで学習:
- 従来のAIモデル開発では、大量のデータを用いてモデルを学習させる「教師あり学習」が一般的でした。
- しかし、DeepSeek は、この常識を覆し、DeepSeek-V3-Base をベースに、強化学習のみで学習させるという大胆なアプローチに挑戦しました。
- この実験的なモデルが、「DeepSeek R1-Zero」です。
- 「GRPO」+ ルールベース報酬:効率的な学習
- DeepSeek R1-Zero の学習には、DeepSeek が独自に開発した「GRPO(Group Relative Policy Optimization)」という強化学習アルゴリズムが使われています。
- GRPOは、従来の手法に比べて計算コストが低く、効率的な学習を可能にします。
- さらに、DeepSeek R1-Zero の学習では、AIが生成した文章の正しさや形式の正しさのみに基づいて報酬を与える「ルールベース報酬」を採用しました。
- このアプローチにより、AIは人間が意図した推論をすることなく、より効率的に推論能力を獲得することができました。
- まるでテトリスのAIが、ブロックを消すことに特化して学習するように、DeepSeek R1-Zero は、数学の問題を解くことに特化して学習しました。
- DeepSeek R1-Zero が得たもの:ハッとする瞬間と高度な推論能力:
- 驚くべきことに、DeepSeek R1-Zero は、強化学習のみで、自己検証、内省、長い思考連鎖(CoT)の生成といった、人間のような高度な推論能力を獲得しました。
- さらに、DeepSeek R1-Zero は、途中で自分の思考を見直し、別の解法を試すという、まるで人間が「ハッ!」とする瞬間(Aha Moment)のような動作を見せるようになりました。
- しかし一方で、出力が読みにくい、複数の言語が混ざってしまうなどの課題も見つかりました。
2. DeepSeek R1:課題解決とさらなる性能向上
DeepSeek R1-Zero の成功を受けて、DeepSeek は、さらなる性能向上を目指し、DeepSeek R1 の開発に着手しました。DeepSeek R1 は、DeepSeek R1-Zero が抱えていた課題を解決し、より実用的なAIモデルに進化しました。
- コールドスタート問題への対処:SFT (教師付き微調整) の導入
- DeepSeek R1-Zero は、学習初期の段階で、不安定な学習状態に陥る「コールドスタート問題」を抱えていました。
- そこで、DeepSeek R1 では、学習の初期段階に、人間の知識に基づいた少量のCoT(Chain-of-Thought)データセットを使い、「教師あり学習(SFT)」を実施しました。
- このSFTにより、DeepSeek R1 は、DeepSeek R1-Zero よりも安定した学習と、より人間が読みやすい出力ができるようになりました。
- 言語一貫性報酬の導入:
- DeepSeek R1-Zero が抱えていた、出力に複数の言語が混ざってしまう問題に対処するため、DeepSeek R1 では、強化学習の報酬に「言語一貫性報酬」を追加しました。
- これにより、DeepSeek R1 は、より自然で理解しやすい文章を生成できるようになりました。
- 二段階の強化学習:
- DeepSeek R1 は、SFTで初期化された後、再度強化学習で強化されました。
- これにより、DeepSeek R1 は、高い推論能力を維持しながら、より安定した性能と、人間にとっての使いやすさを実現しました。
- 二段階のSFT:
- DeepSeek R1 は、強化学習で性能を上げた後、再度SFTを実施しています。
- これにより、推論能力を維持しつつ、ライティングなどの汎用的なタスク性能を向上させました。
3. DeepSeek R1-Distill:軽量モデルへの蒸留
DeepSeek R1 は高性能ですが、モデルサイズが大きいため、一般的なPC環境では動作させることが難しいという課題がありました。そこで、DeepSeek は、DeepSeek R1 の知識を、より小さなモデルに転移させる「蒸留」という技術を活用しました。
- DeepSeek R1 の知識を軽量モデルに転移:
- DeepSeek R1 が学習した高度な推論能力を、DeepSeek R1-Distill という軽量モデルに移し替えることに成功しました。
- これにより、家庭用PCでもDeepSeek R1の性能を体感できるようになりました。
- SFTによる蒸留:
- DeepSeek R1-Distill は、DeepSeek R1 が生成したデータを元に、教師あり学習で学習されています。
- 蒸留モデルに対する強化学習は行わず:
* 興味深いことに、DeepSeek は、蒸留モデルに対して強化学習を適用する実験は行っていないとのことです。 - これは、強化学習には、ある程度の性能を持つベースモデルが必須であるという、DeepSeek の考えに基づいています。
まとめ
データの使用に関する記載が少ないため情報の取り扱いには慎重にならざるを得ませんが、AI業界にとって大きな一歩になるはずです。
このように、新世代のモデル技術が一気に拡散・模倣されると、世界のAI市場は「極度の集約」と「急速な分散」の両方向に揺れ動く可能性が高いです。
巨大投資を続けられるプレイヤーが天文学的なパラメータ数のモデルを作り上げ、少数企業による寡占状態をさらに強めるかもしれませんね。
🕒 「生成AIお悩み相談室」30分無料相談のご案内
\今だけの特別枠、予約殺到中!/
「生成AIを導入したいけど何から始めれば?」「ChatGPTをビジネスに活用する方法は?」「コスト削減のためのAI活用法を知りたい」
このような疑問や課題をお持ちではありませんか?
当社の生成AIスペシャリストが、あなたのビジネス課題に合わせた具体的なアドバイスを完全無料で提供します。
✅ 30分で得られる価値
- 貴社の業務に最適な生成AI活用法の提案
- コスト削減・業務効率化のための具体的なステップ
- 競合他社に差をつけるAI戦略のヒント
- 内製化に向けたロードマップの相談
✅ 参加者からの声
「相談後すぐに実践できるアイデアが得られました」
「具体的な導入ステップが明確になり、迷いがなくなりました」
【完全無料・30分枠】数に限りがございますので、お早めにご予約ください。
👉 今すぐ無料相談を予約する 👈
※予約は先着順・毎月限定5枠のみ。キャンセル待ちにならないようお早めに。